Reference: MySQL 8.0 Reference Manual
SQL is the language we use to talk to the Database Management System
1. Database
-- 创建数据库
CREATE DATABASE db_1;
CREATE SCHEMA 'db_1';
-- 删除
DROP DATABASE db_1;
-- 选择数据库
use db_1;
2. Table
2.1 创建、删除、描述
在对数据库或表单的创建、删除操作中,可在对象名前加上 if exists/if not exists,以避免由重复操作导致的报错。
-- 创建
create table if not exists 表单名(
列1名 数据类型 [修饰1],
列2名 数据类型 [修饰2]
);
-- 删除
drop table if exists 表单名;
-- 描述:输出各列的定义信息(包括列名、数据类型、是否允许空值、默认值等)
describe 表单名;
(1) 数据类型:(示例中有详细说明)
int(size) | 整形 | size 仅有显示意义,需与 zerofill 等修饰配合使用 |
decimal(s1, s2) | 浮点数 | 准确值;s1 表最大总位数,s2 表小数点后的位数,必填; 对于超出位数进行四舍五入,例如 decimal(5, 2) 34.439$\to$34.44 |
float | 浮点数 | 近似值;s1 s2 可不填;近似值会导致潜在的计算问题,会导致结果的不准确(尽管偏差微小),因此对于需要用于计算的精确浮点数,尽量使用 decimal 来存储 |
double | 浮点数 | 同上 |
char(size) | 字符 | 存储空间固定 = size |
varchar(size) | 字符 | 存储空间不固定,size 仅规定其上限 |
enum(...) | 枚举 | 类似单选,插入数据时只能插入其定义的一个元素;可用 index 表示元素位置,从 1 开始依次对应各个元素 |
set(...) | 集合 | 多选,能插入多个元素 |
date | 时间 | ‘YYYY:MM:DD’ |
datetime(size) | 时间 | ‘YYYY:MM:DD HH:MM:SS’,size 选填,表示精确到秒的小数点后几位 |
(2) 修饰:
primary key (c1) | 写在第一行,表示将 c1 设置为主键,每个表的主键唯一(主键值必须唯一标识表中的每一行,且不能为 NULL) |
primary key | 写在常规修饰区域,效果同上 |
zerofill | 补0,仅更改显示效果;例如对于 int(3) zerofill 输入1,则会显示001 |
not NULL | 表明任意行数据在该列的值都不能为空 |
auto_increment | 表示键值顺序递增;可修饰在 not NULL 之后,这样插入新数据时即使没有给该列赋值,也能成功创建,这条新数据的该列值 = max(该列已有值) + 1 |
default X | 设置默认值为 X(例如 NULL, ‘’, 0, …) |
comment | 为列添加注释 |
unsigned | 标记为无符号数据,默认 signed |
示例:
create table if not exists T1(
primary key (id),
id int(10) not NULL auto_increment,
n1 int,
n2 int(10) zerofill,
n3 int unsigned comment 'unsigned int',
n4 decimal(5,2),
n5 float,
c1 char(4),
c2 varchar(4) default null,
color enum('white', 'red', 'green'),
func set('eat', 'sleep', 'fly') default 'eat,sleep'
)
注意事项: 插入 enum & set
insert into table1 (color) values ('red'); -- 不可插入多个
insert into table1 (color) values (1);
insert into table1 (func) values ('eat,sleep,fly'); -- 逗号前后不要留空格
2.1.1 创建一个简单表
| N | id |
|---|---|
| A | 0 |
| B | 1 |
select 'A' as N, 0 as id
union
select 'B' as N, 1 as id
2.1.2 约束(主键+外键)
创建主键、外键约束
CREATE TABLE Persons (
ID INT NOT NULL,
Name VARCHAR(25),
CONSTRAINT PK_Person PRIMARY KEY (ID)
)
CREATE TABLE Orders (
OrderID INT NOT NULL,
OrderNumber INT NOT NULL,
PersonID INT,
CONSTRAINT PK_Order PRIMARY KEY (OrderID),
CONSTRAINT FK_PersonOrder FOREIGN KEY (PersonID)
REFERENCES Persons(ID)
)
删除约束
ALTER TABLE Persons
DROP CONSTRAINT PK_Person
修改约束
ALTER TABLE Orders
ADD
2.2 增删改
修改表名
alter table table1 rename to table2;
添加行 (插入数据)
insert into table1
values
(r11, r12, r13),
(r21, r22, r23);
添加列
-- 添加到第一列
alter table table1 add column col_new int(10) not NULL default 0 first;
-- 添加到特定列之后
alter table table1 add column col_new int(10) not NULL default 0 after col2;
-- 添加到最后
alter table table1 add column col_new int(10) not NULL default 0;
-- 添加一列数据,其数值为已知列的运算结果
-- virtual 表示值不是真实存储的,每次读取动作的时候会重新计算
-- stored 表示值是实际存储的,不会随着其他列值的更新而更新
alter table orders
add column sum_price decimal(9,2) as (unit_price * quantity) [virtual|stored]
after quantity;
修改列
-- 整体修改
alter table table1 change column col1 col_new int(10) not NULL default 0;
-- 属性修改(名称不改)
alter table table1 modify column col1 varchar(100);
-- 修改列为主键
alter table table1 add primary key(col1);
删除列
alter table table1 drop column col1;
2.3 复制
-- 完全使用原表单的部分列构建新表单
create table table2 as (select t1c1, t1c3 from table1);
-- 部分使用原表单的列构建新表单
create table table2(
t2c1 int(10),
t2c2 varchar(100)
) select distinct t1c3 as t2c2 from table1; -- t1c3 是 table1 的
2.4 行列转换
2.4.1 行转列 unpivot()
这是一个 SQLServer 函数,在 MySQL 里用不了
目标
| ID | Phone1 | Phone2 |
|---|---|---|
| 1 | 11 | 12 |
| 2 | 21 | 23 |
转化为
| ID | Phone_num | Phone_type |
|---|---|---|
| 1 | 11 | Phone1 |
| 1 | 12 | Phone2 |
| 2 | 21 | Phone1 |
| 2 | 22 | Phone2 |
代码与解释
根据目标需求,我们需要:
- 创建两个新列 Phone_num, Phone_type
- 删除旧列 Phone1 与 Phone2,并将它们的列名作为新列 Phone_type 的元素
- 结合 ID 填充这两个新列
select * from Customers
unpivot (
-- 创建新列: Phone_num
Phone_num
-- 创建新列: Phone_type
-- 删除旧列: Phone1, Phone2,并将它们的列名作为 Phone_type 的值
-- 遍历这些列名,结合ID,查找旧表中的电话数据填入 Phone_num
for Phone_type in (Phone1, Phone2)
) as up;
2.4.2 列转行 pivot()
该函数在填充数据时必须使用聚合函数,这意味着只能处理数值元素(详见代码部分的注释)
目标与上部分相反:
| ID | Phone_num | Phone_type |
|---|---|---|
| 1 | 11 | Phone1 |
| 1 | 12 | Phone2 |
| 2 | 21 | Phone1 |
| 2 | 22 | Phone2 |
| ID | Phone1_ | Phone2_ |
|---|---|---|
| 1 | 11 | 12 |
| 2 | 21 | 23 |
根据目标,我们需要:
- 删除旧表的 Phone_num, Phone_type 两列,并将它们的元素作为新表的列名
- 创建这两个新列 Phone1, Phone2
- 结合 ID 填充新列
select p.ID,
p.Phone1 as Phone1_,
p.Phone2 as Phone2_
from Customers
pivot (
-- 删除旧列: Phone_nume
-- 这里必须是一个聚合函数 Aggregation,例如 sum() avg()
-- 因此这要求电话号码的格式必须为数字,不能是字符串
sum(Phone_num)
-- 创建新列: Phone1, Phone2
-- 删除旧列: Phone_type
-- 遍历这些列名,结合ID,查找旧表中的电话数据填入新表
for Phone_type in (Phone1, Phone2)
) as p;
2.5 合并 Union
union all
select a1 from T as t1
union all
select a2 from T as t2
unoin / unoin distinct 去重合并(根据主键判断)
2.6 保存为 .csv
select * from SKU_layersDailyPicking
into outfile '/tmp/SKU_layersDailyPicking.csv' -- 绝对路径
fields terminated by ','; -- 指定分隔符(默认为 Tab)
3. Record (Data)
3.1 增删改
3.1.1 添加 INSERT
-- 插入一条有两列的record
insert into table1 values (column1_value1, column2_value1);
-- 插入多条数据
insert into table1 values
(a11, a12),
(a21, a22);
-- 插入一条仅为指定列赋值的record
insert into table1(col1, col2) values (a31, a32);
-- values中的顺序不需要符合从左到右
insert into table1(col2, col1) values (a42, a41);
3.1.2 删除 DELETE
delete from table1; -- 删除全部数据记录
delete from table1 where id = 6; -- 将对应id的数据行删除
删去 Drinks(name, manf) 中的那些有多个生产商的饮料
delete from Drinks
where name in (
-- MySQL不支持对一个表同时进行查找和删除
-- 因此需要再套一层中间表
select t.name from(
select d1.name
from Drinks d1, Drinks d2
where d1.name = d2.name and d1.manf <> d2.manf
) as t
);
注意!当sql_safe_updates = true时将无法进行删除/修改操作,需将其设置为false
set sql_safe_updates = false;
3.1.3 修改 UPDATE
Drinks(name, manf)(饮料名–生产商)修改M1生产商所有产品的 name 属性
update Drinks set name = 'Cola_2022' where manf = 'M1';
4. Query (Select)
4.1 Overall
select col1
from table1
(where) condition
(group by) col2
(having) condition
(order by) sorting
(limit)
4.2 Components
(1) Select (into) from
-- 从表单中选取所有数据
select * from table1;
-- 根据选取的内容创建一张新表单
select * into table2 from table1;
-- 选取用户id和姓
select user_id, last_name from users;
-- 输出用户的全名
select concat(first_name,' ',last_name) as full_name
from users;
-- 统计每个位置有多少用户
select location, count(loaction) from users
group by location;
-- 查看该列有哪些不一样的数值(非重复值)
select distinct col1 from table1;
correlation name
select O.order_id, U.user_name
from orders O, users U
where O.user_id = U.user_id;
select ... from 中还可以插入绝大部分的 functions (详见 Section 5)
(2) Where
select col from table1 where (限制条件);
多个条件之间可以用 or/and 并列,用 not 表否定
表示大小关系(时间也可以用符号比较):
col = 10col <> 10不等于col between 10 and 20限定范围col is NULLcol is not NULL
表示从属关系:
col in (9, 10, 11)col in (select col2 from table2)
比较字符串:
col like '%soft%'选取包含soft字段的元素,例如banksoft.col like 'soft%'选取以soft字段开头的元素col like 's%t'选取以s开头t结尾的元素col_name like 's_ft%'下划线表示任意字符 (可以使用多个)
AND vs. OR: AND 优先级大于 OR,也就意味着
Id=9 OR Id=10 AND Price>15
-- 等同于
Id=9 OR (Id=10 AND Price>15)
因此需要使用括号 () 来提升可读性
(3) Group by
根据商品状态分组,统计各不同状态的数据条目的数量及其均价
select
prod_status, count(*), avg(prod_price)
from products
group by prod_status
-- 修改: 同时能够显示出各组内数据的商品名
select
GROUP_CONCAT(distinct prod_name), -- distinct 去重
count(*), avg(prod_price)
from products
group by prod_status
(4) Having
用于对已经经过选取、条件限制、分组之后的数据添加进一步的限制要求
select prod_status, sum(v1) as v1_sum, sum(v2) as v2_sum
from table1
where v3 >= 0
group by prod_status
having v1_sum + v2_sum >= 100;
(5) Order by
-- 升序排列(默认)
select * from table1 order by col1 (asc);
-- 降序排列,并取前三个最大的
select * from table1 order by col1 desc limit 3;
-- 符合排列,先根据col1升序,在其排序结果内再根据col2降序
select * from table1 order by col1 asc, col2 desc;
复合示例:
-- 取出table1中,生产日期大于2014年的物品中,价格前三贵的物品的名字
select col_name from table1
where
col_date > '2015-1-1'
order by col_price desc limit 3;
(6) Limit
-- 取前n条数据
select col1 from table1 limit n;
-- 取第n+1-n+m+1条数据
select col1 from table1 limit n, m;
limit 后的 n/m 都只能为常量/输入或自定义变量,不能为表达式
4.3 子查询 Subquery
嵌套在 FROM, WHERE or HAVING 中,以解决 query 依赖问题 值判断: =, >, <, <>(不等号), … 集合判断: in, any, all, exists
-- 查看名字以“A”开头且电话号码以“5”结尾的顾客的信息
select * from (
select * from Customer
where name like 'A%'
) as tem_C
where temp_C.phone like '%5';
(1) IN
-- 查看状态为新上架的商品订单
select * from orders
where product_id in (
select product_id from products
where sale_status = 'New'
);
(2) EXISTS From Drinks(name, manufacturer), Sells(café, drink, price)
-- 查看售价高于5元的drink信息
select * from Drinks D
where exists (
select * from Sells
where drink = D.name and price > 5
);
执行顺序: (1) 首先执行一次外部查询,并缓存结果集,如 select * from Drinks D (2) 遍历外部查询结果集的每一行记录,代入子查询中作为条件进行查询 (3) 如果子查询有返回结果,则EXISTS子句返回TRUE,这一行记录可作为外部查询的结果行,否则不能作为结果行
(3) 嵌套子查询 通过 Customers$\to$(customer_ID)$\to$Orders$\to$order_number$\to$OrderItems 来查找购买了牙刷的顾客
select Customer_name from Customers
where CustID in (
select Customer_ID from Orders
where Order_number in (
select order_num from OrderItems
where prod_name = "Toothbrush"
)
)
4.4 Set Operation
并集、交集、差集
( subquery ) UNION ( subquery )
( subquery ) UNION ALL ( subquery ) -- 允许重复元素
( subquery ) INTERSECT ( subquery )
( subquery ) EXCEPT ( subquery )
From
Likes(customer, drink),Sells(cafe, drink, price)Frequents(customer, cafe)
查找出 customer-drink 数据集,满足顾客喜欢该饮料且曾去咖啡店喝过
(select * from Likes)
INTERSECT(
select customer, drink from Sells S, Frequents F
where S.cafe = F.cafe
);
5. Function
MySQL有丰富的函数支持,例如仅对于字符串的处理,就有mysql.doc
5.1 Case 分组
select
col_name,
price,
(case
when col_price < 20 then '0-20'
when col_price >= 20 and col_price < 40 then '20-40'
else 'too expensive'
end) as price_group
from
table1;
5.2 Math
POW(4, 2); -- 幂方(平方): 4^2=16
SQRT(4); -- 开方
MOD(4, 2); -- 取余: 4%2=0
DIV(4, 2); -- 整除: 4//2=0
ABS(-1); -- 绝对值
FORMAT(1.123, 2) -- 保留两位小数,以字符串格式返回
ROUND(1.123, 2) -- 保留两位小数,以浮点型格式返回
5.3 Aggregation
SUM() AVG() COUNT() MIN() MAX() GROUP_CONCAT()
AVG 在 Aggregation 中使用 CASE WHEN ELSE
例如:统计好评在所有有效评价中的占比
comm=ENUM(‘Good’,'Bad','None'),有效评价不包括'None'- 如果没有评价,则返回
NULLselect avg(case when comm='Good' then 1 when comm='Bad' then 0 else null end) as good_rate from Comments
SUM
select sum(c1) as sum1, sum(c2) as sum2
from table1;
SUM() 可用于统计某一条件的成立次数(Leetcode 1173)
-- 统计 col1,col2 值相等的数据的数量
select sum(col1 = col2) from table1;
同理,AVG() 等亦可,但是 COUNT() 依旧会统计 False,因此需要利用其不会统计 NULL 的特性(详见下个代码框中的第三行)
COUNT
select count(*) from table1; -- 数据总个数
select count(col1) from table1; -- 特定列的非空数据个数
select count(distinct col1) from table1; -- 特定列去除重复值后的数据个数
select count(col1 > 0 or null) from table1; -- 特定列数值大于0的数据个数
去重复
-- 查看5号商品有几种不同的售价
select count(distinct product_price) from products
where product_id = "005";
NULL NULL 不会参与aggregation,除非当所选值均为 NULL 时则会返回 NULL。
GROUP_CONCAT 文字聚合
-- 查看每个买家购买的商品种类(根据字符排序)
select user_id, group_concat(distinct product_name order by product_name)
from orders
group by user_id
5.4 Datetime
DATE_ADD(dt, inerval 1 day); -- 增加一天
LEFT(dt, n); -- 通过调整n实现获取年份、月份
YEAR(dt); -- 获取年份
DATEDIFF(dt1, dt2); -- 两个日期之间的天数
DATE_FORMAT(datetime, format); -- 将datetime转化成指定format的string
STR_TO_DATE(str, format); -- 按照指定format将string转化为datetime
str_to_date('Thursday, February 17, 2022', '%W, %M %d, %Y')
%Y | 年 2022 |
%y | 年 22 |
%M | 月 January |
%m | 月 01 |
%b | 月 Jan(三字符缩写) |
%W | 周 Monday |
%w | 周 0(Sunday), 1(Monday), … |
%a | 周 Mon(三字符缩写) |
%d | 日 1 |
5.5 String
CHAR_LENGTH(str); -- 字符串长度
LEFT(str, n); -- 取左侧n个字符(可用于datetime)
CONCAT(str1, str2); -- 合并/连接字符串
REGEXP_LIKE(str, '正则表达式'); -- 判断字符串是否符合正则表达式
</details>
REGEXP_LIKE() '正则表达式'
点击展开示例
筛选出所有合法的邮箱地址: - 以字母开头 - 以 `@leetcode.com` 结尾 - 其他位置只包含字母、数字、`_`、`.`、`-` ```sql select email from Infos where regexp_like(email, '^[A-Za-z]+[A-Za-z0-9\_\.\-]*@leetcode.com') ```5.6 NULL
IFNULL(col, 0); -- 如果对应列的值为 NULL 则返回0,否则返回该值
使用 select 语句时,如果遇到以下需求:若查询不到匹配选项,则返回 NULL。可以使用嵌套 select 的方式:
select (select ...) as num;
5.7 Over (window function)
Grammar:
func(col_name) OVER(
partition by ...
order by ...
{rows|range} ... -- window frame
) as new_col_name
5.7.1 Functions before OVER
有非常丰富的函数可以使用,详情点击。这里仅举几个常用例子:
| prod_name | price | class |
|---|---|---|
| apple | 3 | fruit |
| chips | 5 | snack |
| banan | 3 | fruit |
(1) rank()
新建一列,显示价格降序排名
SELECT prod_name, price
rank() OVER(ORDER BY price DESC) as price_rk
FROM Products
| prod_name | price | price_rk |
|---|---|---|
| chips | 5 | 1 |
| banan | 3 | 2 |
| apple | 3 | 2 |
(2) row_number()
与 rank() 功能类似,但能解决 rank() 中因为数值相等所导致的排名重复的问题
SELECT prod_name, price
row_number() OVER(ORDER BY price DESC) as price_rk
FROM Products
| prod_name | price | price_rk |
|---|---|---|
| chips | 5 | 1 |
| banan | 3 | 2 |
| apple | 3 | 3 |
(2) agg()
将 aggregation 应用在分组上(下面这例子没有意义,只是为了举例而举例)。注意: 这种分组不会把一个 class 中的所有元素整合到一起(例如 group by 的效果),而是在保留原表格信息的基础上添加了一列
SELECT prod_name, class,
count(*) OVER(PARTITION BY class) as count_num
FROM Products
| prod_name | class | count_num |
|---|---|---|
| apple | fruit | 2 |
| chips | snack | 1 |
| banana | fruit | 2 |
first_value() last_value()
新建一列 high_price_prod 显示每组最贵的商品的名字
SELECT prod_name, class, price
first_value(prod_name) over(
partition by class
order by price desc
) as high_price_prod
FROM Products
5.7.2 Window frame
Similar to a slicing window, instead of focus on each line, it pays attention to a range based on the current line (可以实现诸如累加、取前后共三个月的均值等效果)
注意: 由于 Table 本身是不带有顺序的,而 window frame 的创建基于一个排好序的表格,因此 使用 window function 之前必须排序,不管是在 over() 里还是在后面
ROWS
rows between lower_bound and upper_bound
- lower_bound:
n proceding,unbounded preceding,current row - upper_bound:
m following,unbounded following,current row
Examples:
-- window1: previous n rows + current row + m rows following
rows between n preceding and m following
-- window2: from 1st row to current row
rows between unbounded preceding and current row
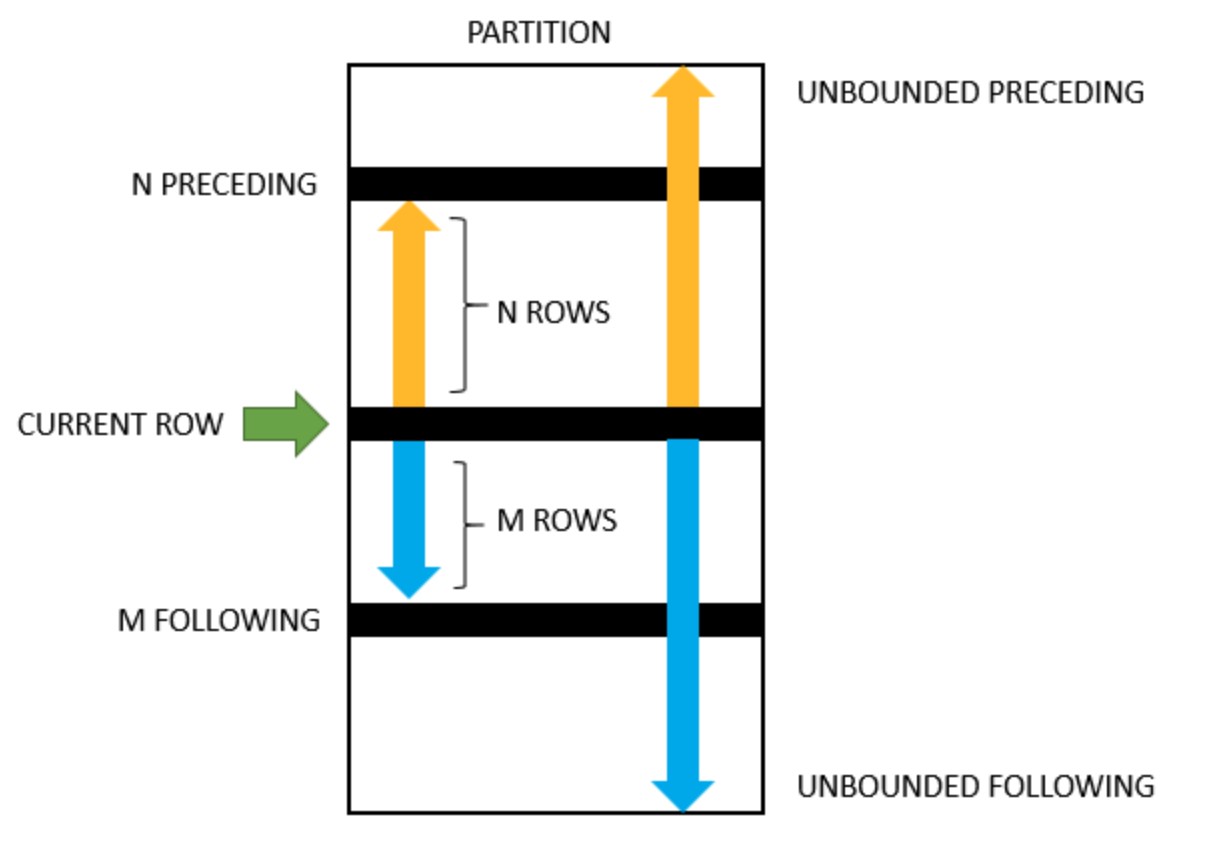
Ex.1: For each month and product class,计算其前后共三个月的平均销售收入
select month_num, prod_class, avg(income) over(
partition by prod_class,
order by month_num asc,
rows between 1 preceding and 1 following
) as avg_income
from Sell_Table
Ex.2: For each month,计算累积收入
select month_num, sum(income) over(
rows between unbounded preceding and current row
)
from Sell_Table
order by month_num asc
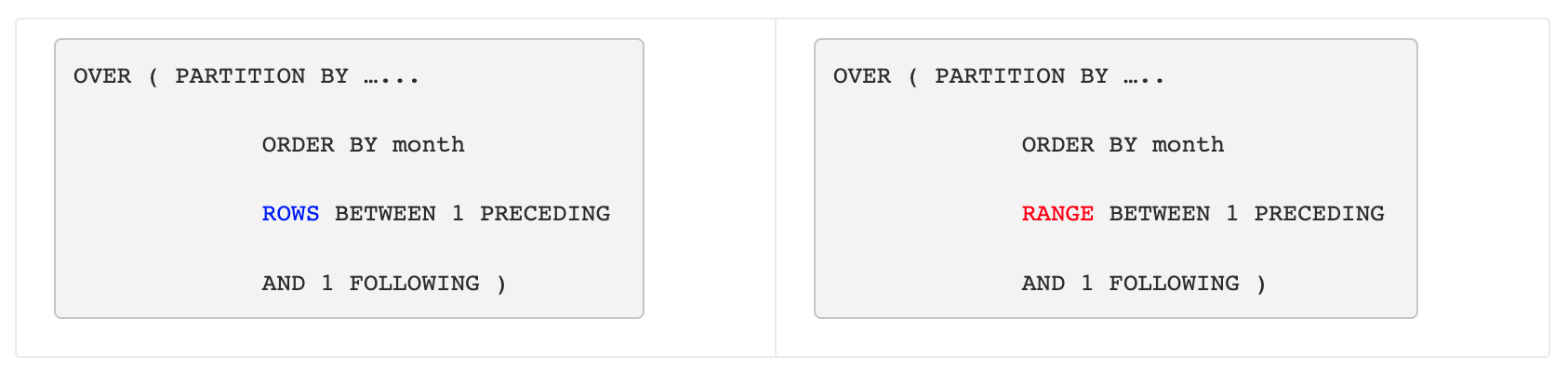
RANGE
range between lower_bound and upper_bound
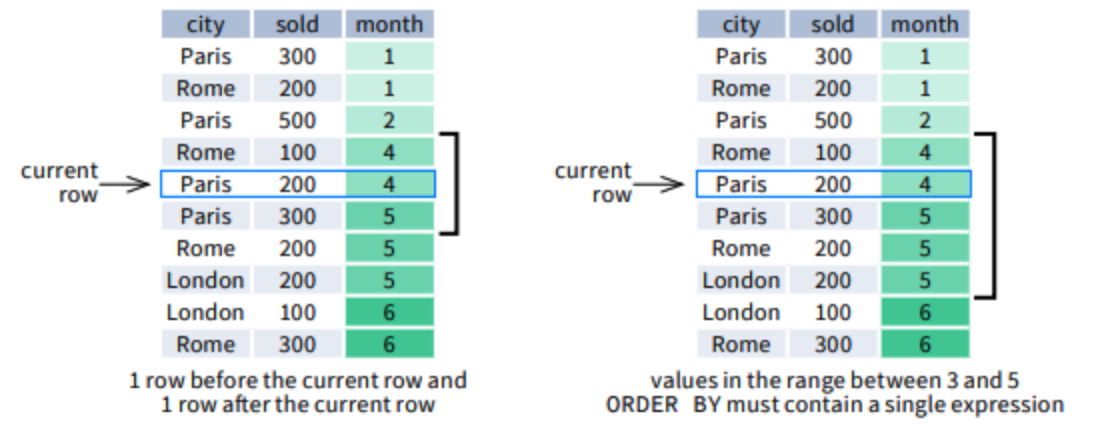
ROWS 通过置顶前后行数来创建 window frame,而 RANGE 则通过指定列(已排序)的数值范围来创建 window frame
例如下左半边的范围是严格的前后各一行 + 当前行(3 rows),而右半边的范围则取决于具体月份,例如对于 Paris-200-4 这一行,其范围将会包括月份为3-5的所有行(5 rows)
6. Constraints
6.1 Foreign Keys
6.1.1 在创建表单时添加
CREATE TABLE Drinks (
name CHAR(20) PRIMARY KEY,
manf CHAR(20)
);
CREATE TABLE Sells (
cafe CHAR(20),
drink CHAR(20),
price REAL,
FOREIGN KEY drink REFERENCES Drinks(name)
[on delete reference_option]
[on update reference_option]
);
6.1.2 为已创建好的表单添加
将 T1.c1 与 T2.c2 相关联,其中 T2.c2 必须为主键
alter table T1
add constraint constraint_name foreign key (c1)
references T2 (c2)
[on delete reference_option]
[on update reference_option];
reference_option
RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT
CASCADE操作联动。例如 on update cascade: 当修改 T2.c2 中的某个数据时,T1.c1 所包含改的对应数据都会自动做出相应的修改SET NULL设空值。例如 on delete set null: 当删除 T2.c2 中的某个数据时,T1.c1 所包含改的对应数据都会被设置为空值,这样能够避免整个记录被删掉NO ACTION默认情况,啥都不做
6.2 Attribute-Based Checks
能够添加数值范围的限制,也能添加类似于 Foregin Key + NO ACTION 的限制
CREATE TABLE Sells (
cafe CHAR(20),
drink CHAR(20) CHECK (drink IN (SELECT name FROM Drinks)),
price REAL CHECK (price <= 5.00)
);
7. JOINS
顺序位置:列表的 JOINS 用 on 来表示条件,其后可以再跟条件 where(亦可不跟)
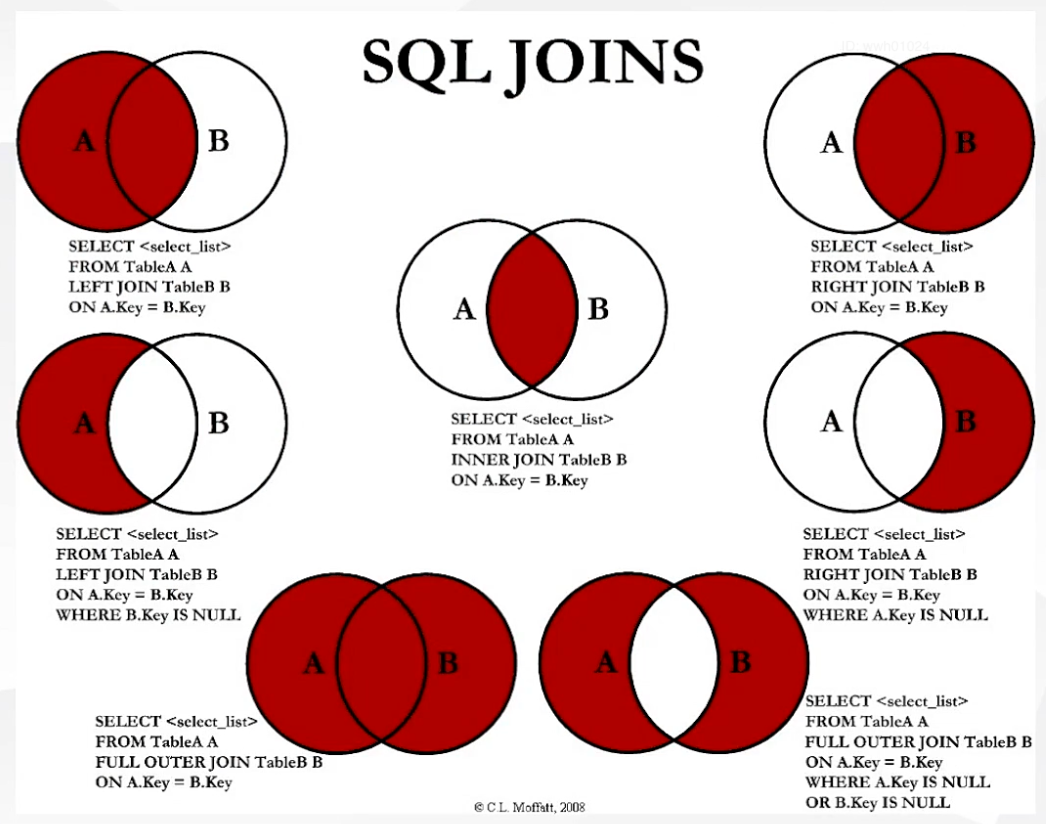
目标:生成新表单 user_name | product_name | unit_price | quantity
users: user_id | user_nameproducts: prodcut_id | product_nameorders: order_id | user_id | product_id | unit_price | quantity
7.1 INNER JOIN (or JOIN)
同时 join 多个 tables
select
user_name, product_name, unit_price, quantity
from
orders inner join (users, products)
on
orders.user_id = users.user_id and orders.product_id = products.product_id;
或者
-- or
select user_name, product_name, unit_price, quantity
from orders
inner join users on orders.user_id = users.user_id
inner join products on orders.product_id = products.product_id;
7.2 NATURAL JOIN
功能类似 INNER JOIN,能自动根据两个表中具有相同名称的列进行匹配
select * from orders natural join users;
7.3 LFTT/ RIGHT JOIN
= LEFT/ RIGHT OUTER JOIN
保留左/ 右表单的全部内容,并取另一张表单中满足对应条件的数据。
以下面这段代码为例,
products包含2个商品(A,B)的名称和价格,orders包含4条订单信息(数量:A1,B2,C1)。LEFT JOIN的结果为一个包含3行数据的表单:左半边相当于在products的基础上添加了一条重复的商品B的名称和价格products包含4个商品(A,B,C,D)的名称和价格,orders包3条订单信息(数量:A1,B1,D1)。LEFT JOIN的结果为一个包含4行数据的表单:左半边等同于products;右半边相当于在orderss的基础上添加了一条null行
select * from products left join orders
on products.product_id = orders.product_id;
-- or
select * from products left join orders
using (product_id);
7.4 FULL OUTER JOIN
保留两个表单的全部内容,为无法匹配的内容填入 NULL
select * from df1 full outer join df2
on df1.col1 = df2.col1
7.5 UNION (ALL)
相比于 JOIN 的横向匹配
- UNION ALL 为纵向数据堆叠,前提是需要堆叠的表单需要由相同的列
- UNION 则会去除重复行数据
select City, Country from Customers
where Country = "Germany"
UNION
select City, Country from Suppliers
where Country = "Germany"
Applications
Compare two tables
使用 INNER JOIN 比较两张 Table 所包含的数据是否完全一致
例如,Table_1 和 Table_2 两张表单,都包含 c1 和 c2 两列。那么可以通过以下代码来比较两张表单的这两列数据是否完全一致:如果以下三个 query 所返回的结果相等,即可认为数据一致
WITH T1 AS (select distinct c1, c2 from Table_1),
T2 AS (select distinct c1, c2 from Table_2)
SELECT count(*) FROM T1 INNER JOIN T2
ON T1.c1 = T2.c1 AND T1.c2 = T2.c2;
WITH T1 AS (select distinct c1, c2 from Table_1)
SELECT count(*) FROM T1;
WITH T2 AS (select distinct c1, c2 from Table_2)
SELECT count(*) FROM T2;
8. NULL
IFNULL(col, 0); -- 如果对应列的值为 NULL 则返回0,否则返回该值
使用 select 语句时,如果遇到以下需求:若查询不到匹配选项,则返回 NULL。可以使用嵌套 select 的方式:
select (select ...) as num;
8.1 Logic and NULL
3-valued logic:
- True (1)
- False (0)
- Unknown (1/2)
Logic calculations:
- AND = MIN
- OR = MAX
- NOT(x) = 1-x
NULL 和任何数值进行比较时,输出的结果都是 Unknown (1/2),例如:
select * from persons where
(age<25) AND (height > 6 OR weight < 150)
对于一个22岁身高未知体重160的人而言:
TRUE AND (UNKNOWN OR FALSE)
= MIN(1, MAX(1/2, 0))
= MIN(1, 1/2)
= 1/2
= UNKNOWN
因此这个人的信息就不会被选到
8.2 输出 NULL 表示空选择
Query 时常会出现查询不到的情况,此时返回空值,如果想要实现返回 null,则可以再嵌套套一个 select,如下例要求查询价格第二高的商品价格,如果查不到则返回 null
select(
select price from Products
order by price desc
limit 1, 1
) as SecondHighestPrice;
9. View
View (视图) 是一种虚拟表,其内容由查询定义,本身并不包含数据。视图看起来和真实的表完全相同,但其中的数据来自定义视图时用到的基本表,并且在打开时动态生成。与直接操作基本表相比,视图具备以下优点:
- 提高数据安全性:在设计数据库时可以针对不同的用户定义不同的视图,使用视图的用户只能访问他们被允许查询的结果集
- 数据独立:视图的结构定义好之后,如果增加新的关系或对原有的关系增加新的字段对用户访问的数据都不会造成影响
例如对以下数据表: Frequents (customer, cafe), Sells (cafe, drink, price) 创建视图 CanDrink (customer, drink) 以查看顾客可能喝的饮料
CREATE VIEW CanDrink AS
SELECT customer, drink
FROM Frequents, Sells
WHERE Frequents.cafe = Sells.cafe;
base table 的 select 操作可以对视图使用,方法同 Section 3. Search
9.1 Table vs. View
联系(修改):
- 对基本表的修改会直接影响视图中对应的内容
- 无法修改基于多个基本表的视图
- 对基于单一基本表的视图的修改会影响基本表中对应的内容
区别:
- 视图是已经编译好的sql语句,没有实际的物理记录;表有
- 表是内容,视图是窗口
- 视图的建立和删除只影响视图本身,不影响对应的基本表
9.2 Materialized View
A materialized view is one that is computed once and its results are stored as a table.
物化视图可以帮助加快严重依赖某些聚合结果的查询,提高性能; 视图是简化设计,清晰编码的东西,并不是为了提高性能。
create materialized view view_table as ...
10. Procedure(函数)
类似于Python中的自定义函数
delimiter //
create procedure proc_name
(proc_parameter, ...)
begin
-- 函数内部的代码块
end//
delimiter ;
proc_parameter 定义输入和输出:
- 格式为:
[IN | OUT | INOUT] param_name param_type IN表输入,OUT表输出,INOUT表示同为输入和输出
分号 ; 在函数内部的代码块中起到分隔语意的作用,但是MySQL默认会将分号视为一个完整语句的结束,因此在需要使用 delimiter 在Procedure前更改结束符 ; $\to$ //,并在Procedure后改回来
10.1 Examples
从 Drinks(name, manf)(饮料名–生产商)中查看任意生产商所生产的饮料种类数
1: 使用 SELECT 输出结果
DELIMITER //
CREATE PROCEDURE GetTypeNumber (IN M VARCHAR(30))
BEGIN
DECLARE typeNumber INT DEFAULT 0;
SELECT COUNT(*)
INTO typeNumber
FROM Drinks
WHERE manf = M;
SELECT typeNumber;
END //
DELIMITER ;
--查看生产商M1所生产的饮料的种类数
CALL GetTypeNumber('M1');
2: 使用 OUT 输出结果
DELIMITER //
CREATE PROCEDURE GetTypeNumber (
IN M VARCHAR(30),
OUT typeNumber INT)
BEGIN
SELECT COUNT(*)
INTO typeNumber
FROM Drinks
WHERE manf = M;
END //
DELIMITER ;
-- 查看生产商M1所生产的饮料的种类数
CALL GetTypeNumber('M1', @typeNumber);
-- 还可以随时查看结果
SELECT @typeNumber;
11. Practice
(Subquery) 利用 where 反向查找价格最低的商品
SELECT
product_name, price
FROM
products
WHERE
price = (SELECT MIN(price) FROM products);
$S(P):$ Score of path $X:$ Travel Distance $Y:$ Transfer Time $Z:$ Train Interval $M=X+Y+Z$
Document Information
- Author: Zeka Lee
- Link: https://zhekaili.github.io/0009/02/01/MySQL-Doc/
- Copyright: 自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)