DataFrame 与 Series 是 pandas 中最重要的两种数据类型
区别:
Series: 一维数据结构,由 index 和 value 组成DataFrame: 二维结构,由 index、column 和 value 组成。
联系:
DataFrame 由多个 Series 组成,无论是行还是列,单独拆分出来都是一个 Series。因此,对数据表的行/列操作,与对数据序列的操作是一致的
1. pandas.DataFrame
# 以下两种方式效果相同
df = df.func(inplace=False)
df.func(inplace=True)
通用参数
inplace: 默认为 False,表示函数操作不会改变 df,而是创建了一个临时对象。True 表示函数操作会应用在 df 本身
输出设置
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示1000列
pd.set_option('max_columns',1000)
# 显示所有行
pd.set_option('display.max_rows', None)
# 显示1000行
pd.set_option('max_rows',1000)
1.1 Create
df = pd.DataFrame()
df = pd.DataFrame(colums=['col_1', 'col_2'])
# Create from Array()/ Dictionary()
df = pd.DataFrame(np.array([[1,2], [3,4]]), colums=['col_1','col_2'], index=['a','b'])
df = pd.DataFrame({'col_1':[1,2],'col_2':[3,4]}, index=['a','b']) # 不填index则默认为下标,从0开始
| col_1 | col_2 | |
|---|---|---|
| a | 1 | 3 |
| b | 2 | 4 |
Create from pd.Series()
- Method 1
sr1 = pd.Series([1], index=['a'])
sr2 = pd.Series([1,2], index=['a','b'])
df = pd.DataFrame({'col_1':sr1,'col_2':sr2})
| col_1 | col_2 | |
|---|---|---|
| a | 1 | 1 |
| b | NaN | 2 |
- Method 2
df = sr.to_frame('col_1') # 相当于给序列加了个列标题,从而变成了表格
Create from .csv
df = pd.read_csv('地址')
index_col='列名'指定某一列为行索引parse_dates=['列名'])将指定列字符串格式的时间转换为datetime格式header=None指定程序不将csv文件的第一行读取为列名na_values=['None','null']指定程序将一些特定字符串视为NaN
1.2 Transform & Save
Transform to np.array()
arr = df.values
Save to .csv
df.to_csv('fileName.csv')
header=False不输出列名index=False不输出行名
Save to .xlsx
writer = pd.ExcelWriter('fileName.xlsx')
df1.to_excel(writer, "sheetName1")
df2.to_excel(writer, "sheetName2")
writer.save()
1.3 Modify
1.3.1 添加数据(行/列)
添加行
df = pd.DataFrame(columns=['c1','c2']) # 添加第一行: 各元素相同(两种方式) df.loc['a1'] = 1 df.iloc[0] = 1 # 添加第二行: 自定义各元素()(两种方式) df.loc['a2'] = [1, 2] df.iloc[1] = [1, 2]
| |c1 |c2 | |–|—–|—–| |a1|1 |1 | |a2|1 |2 |
# 添加第三行: 只为特定位置添加一个元素
df.loc['a3', 'c2'] = 1
| c1 | c2 | |
|---|---|---|
| a1 | 1 | 1 |
| a2 | 1 | 2 |
| a3 | NaN | 1 |
添加列
df['c3'] = 0 # 添加一列(个元素相同) df['c4'] = [5, 5, 5]
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| a1 | 1 | 1 | 0 | 5 |
| a2 | 1 | 2 | 0 | 5 |
| a3 | NaN | 1 | 0 | 5 |
1.3.2 更改行列
将第一列(指定列)设置为 index
df.set_index('col1')
df.reset_index(inplace=True) # 重新改回默认的数字 Index
将 Index 添加为第一列
df.reset_index(inplace=True)
| index | c1 | c2 | c3 | c4 | |
|---|---|---|---|---|---|
| 0 | a1 | 1 | 1 | 0 | 5 |
| 1 | a2 | 1 | 2 | 0 | 5 |
| 2 | a3 | NaN | 1 | 0 | 5 |
df.index = [] # 更改行名, 可以是 list or array
df.columns = [] # 更改列名
# 单独更改某个或某些行/列名
# df.rename({'old':'new'}, axis=(1 for cols, 0 for rows), inplace=True)
df.rename({'old1':'new1', 'old3':'new3'}, axis=1, inplace=True)
将第二行(指定行)设置为列名
new_header = df.iloc[1] # 提取出第二行
df = df[2:] # 去掉前两行
df.columns = new_header # 设置新的列名
1.3.3 更改/替换元素
df[col1].map(func): 将函数应用于指定列的每个元素 (不会改变 df 自身)
df['col1'].map(str.lower)
df['col2'].map({'A':'Aa', 'B':'Bb'}) # 修改特定元素
df.replace(): 将 A 替换成 Aa, B 替换成 Bb
df.replace(['A','B'], ['Aa','Bb'])
df.apply(func, aixs=0)
将函数 func 应用在指定行(axis=0)或列(axis=1)
# 将第四列平方并以 Series 格式输出
df.apply(lambda row:row[3]**2, axis=1)
# 以 Series 格式输出是否已经成年的信息
df.apply(lambda row:0 if row['Age'] < 18 else 1, axis=1)
def func(row):
out = {}
out['col_x'] = row[1] + row[2]
out['col_y'] = row[1] - row[2]
return pd.Series(out, index=['col_x','col_y'])
df.apply(func, axis=1)
1.3.4 删除数据
df.drop(columns=df.columns[0], inplace=True) # 删除第一列
df.drop(index=df.index[-1], inplace=True) # 删除最后一行
1.3.5 合并 DataFrame
pd.concat([df1, df2], axis=1) # 横向合并
1.4 Arributes (Inspection 查看属性)
df.head(i) # 查看前 i 条数据
df.tail(i)
df.index.values # 查看行名
df.columns.values # 列名
df.values # 值数组
df.T # 转置
df.shape # (n, m) n行m列
df.size # n*m 元素个数
# 查看各列的统计数据(count, mean, std, percentile...)
df.describe()
其他统计值详见 Chp:1.10.2 统计数据
1.5 Access (Slice)
1.5.1 访问行列
访问列
df['columnName'] # 单列
df.columnName
df[['col1','col2']] # 多列
访问行
df.loc['rowName',:] # 单行
df.loc[['row1', 'row2']] # 多行
df.iloc[0:2] # 前两行
# 如果行名是默认的 index
df[0:2] # 前两行
访问元素
df.loc['r1', 'c1'] # 单个元素
df.iloc[[0, 1]][['c1','c2']] # 访问指定位置的四个元素
注意!loc[]
或使用 df.iterrows() 例如,将 df 中 ‘col1’ 列的所有元素赋值为0:
for _, row in df.iterrows():
row.col1 = 0
通过列名访问时出现 KeyError
很可能是列名没有正确输出(例如忽略了前后空格)。例如下一图报错的原因,就是列名前后都特么有空格(下二图) 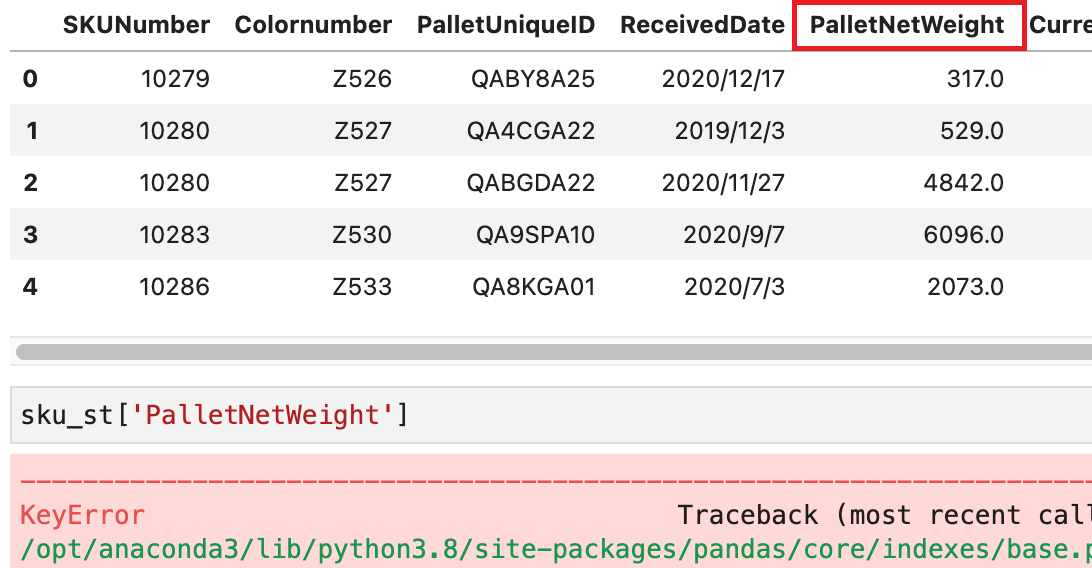

Solution: 打空格或者为所有列名去空格
df.columns = df.columns.str.strip()
1.5.2 索引和切片
如果需要对切片的数据进行修改,必须使用 df = df.XXX.copy()。否则在修改切片的同时也会修改原 DataFrame
# 推荐方式
df.loc['rowName','columnName'] # 使用行列名索引
df.iloc[x,y] # 使用下标索引
df.loc[['r1','r3'], 'c2'] # 使用行列名切片
df.iloc[[0:5], [2:3]] # 使用下标切片
# 不推荐
df['columnName']['rowName']
df.columnName['rowName']
df.sample() # 随机获取一行
df.sample(frac=1, inplace=True) # 随机打乱整个 DataFrame
大部分索引方式创建的都是 view (修改切片会导致原 DataFrame 的同步改变),但是有些索引方式却会创建 copy (修改不会导致原改变)。以下例举会创建 copy 的索引方式:
df.loc['rowName']['colName']
df.iloc[rowIndex]['colName']
df[['colName_1', 'colName_2']][:] # 如果去掉后边的 [:] 就会变成 view
1.6 NaN (Null)
df.isna() # 检查每个数据是否为NaN
df.isna().any() # 检查每列是否包含NaN
df.isna().mean() # 查看每列中NaN的比例
df.isnull() # 等于 isna()
df.notnull() # 取反 isnull()
df.fillna(0, inplace=True) # 为所有NaN赋0
df['col1'].fillna(method='ffill') # propagate last valid observation forward
df['col1'].fillna(method='bfill') # use next valid observation to fill gap
df.dropna(inplace=True) # 删去所有包含NaN的行
df.dropna(how='all') # 删去所有只包含NaN的行
df.dropna(axis=1) # 删去所有包含NaN的列
df.dropna(subset=['col1','col2']) # 删去所有指定列包含NaN的行
1.7 Duplication
1.7.1 Check Duplication
df.duplicated() # 查看是否存在完全重复的数据
df.duplicated(subset=['col1', 'col2']) # 查看是否存在指定列重复的数据
返回一个 pd.Series()
- 其中
True说明对应行的数据重复了,反之False - 可以用
.values的方式将其转换为np.array()
应用:检查在指定两列中,是否存在相同的数据
df.duplicated(subset=['LON', 'LAT']).values.any()
- 其中
L.any()用于检测列表中是否包含True元素,包含则返回True,全元素均为False则返回False- 当然,类似的还可以用于检查是否存在 NaN 数值:
df.isna().values.any()
1.7.2 Remove Duplication
df.drop_duplicates(subset=['LON', 'LAT'], # 将查重范围限制在特定的列中
keep='first', # 保留重复数据的第一个,可以换成 'last'
inplace=True
)
1.8 Plot
画出两列数据,横坐标为 df.index
df['col1'].plot() # index-col1 折线图
df['col1'].plot(kind='bar') # 柱状图
# 直方图(表示数据分布)
df['col1'].plot(kind='hist')
df.hist('col1')
df.hist('col1', by='col_category') # 对每个 category 单独画图
df.plot(x='col_x', y='col_y', kind='scatter') # col_x-col_y 散点图
1.9 Query
1.9.1 Group by
products:
| Category | Price | Name | Amount | |
|---|---|---|---|---|
| 0 | Drink | 4 | Cola | 100 |
| 1 | Snack | 10 | Nut | 50 |
| 2 | Drink | 3 | Fenta | 200 |
Groupby object is kind of like a list of pairs [(group_name, df)]
# grouping = df.groupby(col_to_group_by)
grouping = products.groupby('Category')
for name, df in grouping:
print(name, df.Price.mean())
"""
Drink 3.5
Snack 10
"""
多层分组
grouping_mul = df.groupby(['col1', 'col2', ...])
1.9.1.1 属性 & 方法
属性
grouping = products.groupby('Category')
grouping.indices # 获取各个组所包含的商品 Index
>>> {'Drink':array([0,2]), 'Snack':array([1])}
方法
# 获取某个组所有商品的信息(不包含 `Category` 列)
grouping.get_group('Drink')
| Price | Name | Amount | |
|---|---|---|---|
| 0 | 4 | Cola | 100 |
| 2 | 3 | Fenta | 200 |
1.9.1.2 统计
# 特定列统计值
grouping['Amount'].sum()
# 所有数值类型列的统计值(例如 Name 列就不会被返回)
grouping.sum() # mean() min() max()
| Price | Amount | |
|---|---|---|
| Drink | 7 | 300 |
| Snack | 10 | 50 |
# 为不同的列定义统计方式
grouping.agg({'Price':'mean', 'Amount':'sum'})
| Price | Amount | |
|---|---|---|
| Drink | 3.5 | 300 |
| Snack | 10 | 50 |
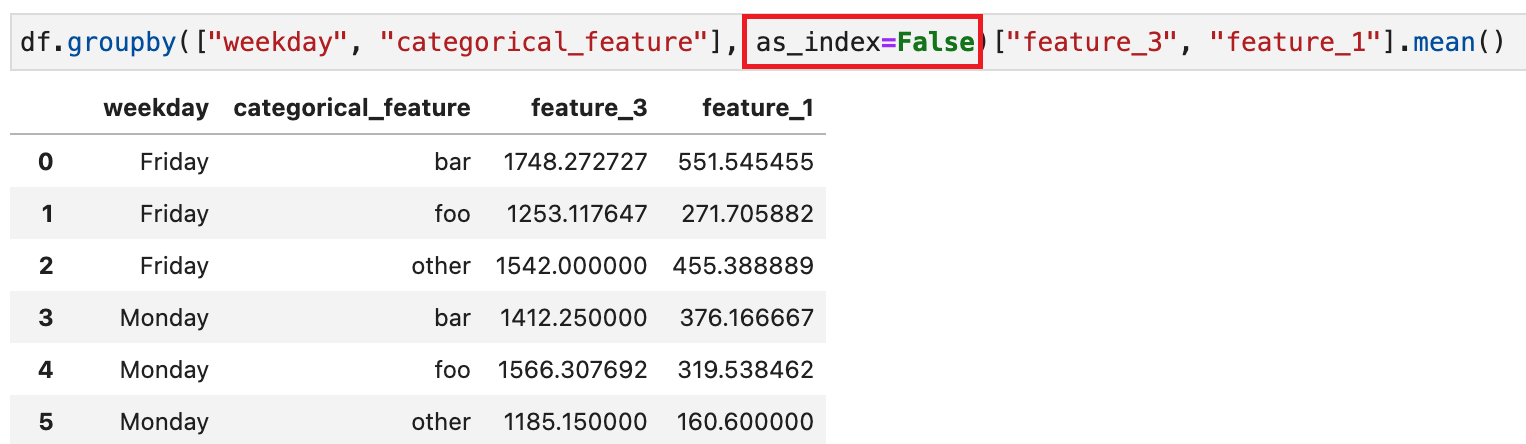
Use
as_index=Falseto return a flat DataFrame
使用前 vs. 使用后 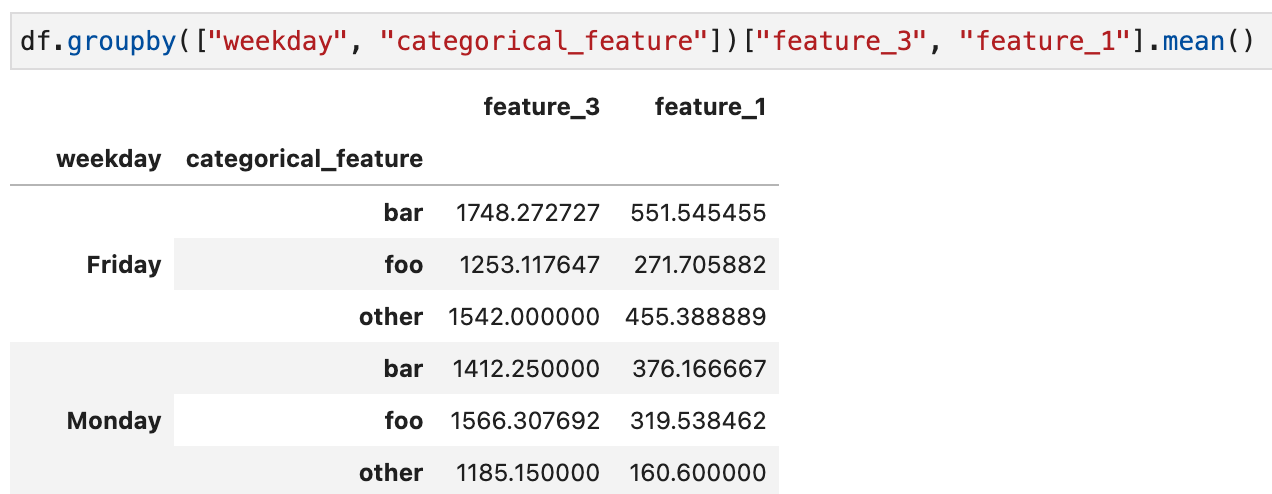
获取各组的某个列在外部函数/lambda上的统计值
df.groupby(col_to_group_by).col_of_interest.apply(func)
col_to_group_by: 分组对象col_of_interest: 根据分组来进行统计的对象func: 应用于统计对象的函数(自定义函数/lambda/其他库的函数)
Ex1: 统计每个航线的平均延误(多种方式)
# 返回数据: 以航线类型为 Index,以平均延误为 Value
flights.groupby('Airline')['Arrival_delay'].apply(np.mean)
flights.groupby('Airline').Arrival_delay.apply(np.mean)
flights.groupby('Airline').Arrival_delay.mean()
# 返回数据: 保持原表的 Index,以平均延误为 Value
flights.groupby('Airline')['Arrival_dealy'].transform(np.mean)
Ex2: 统计每个航线有多少航班的延误时间大于10小时
flights.groupby('Airline')['Arrival_delay'].apply(
lambda ls: np.sum(ls>10)
)
Ex3: 统计每个航班在每个月的平均延误(多层分组)
flights.groupby(['Airline','Month'])['Arrival_delay'].apply(np.mean)
1.9.3 Groupby + Sort
products.groupby('Category').mean().sort_values(
by=['Price'], ascending=False
)
1.9.2 Sort
df.sort_values(by='col1') # 根据指定列做升序排列
df.sort_values(by='col1', ascending=False) # 降序
df.sort_index() # 根据行名做升序排列
# 多列排序
df.sort_values(by=['col1','col2'],
ascending=[False,True]
)
Customized Sorting
使用 pd.Categorical() 创建自定义排序方式
season_order = ["Fall", "Winter", "Spring", "Summer"]
df["season"] = pd.Categorical(df["season"], season_order)
df.sort_values(by="season", inplace=True)
1.9.3 Where (Filter)
df[df['col1']<n] # 筛选出所有满足条件的行
df[(df['col1']<n) & (df['col2']>m)] # 多条件('|'表示或)
多条件必须要用小括号隔离,且不能用 and/or 代替 &/|
示例:
mask1 = df.Poplation > 1000000 # 人口大于一百万的地区
mask2 = df.Region.apply(lambda x: x.startswith('A')) # 名字以 A 开头的地区
df[mask1] # 人口大于一百万的地区的所属行
df[mask1 & mask2] # 人口大于一百万以及名字以 A 开头的地区的所属行
df[mask1 | mask2]
1.9.4 Join (Merge)
Inner Join
select * from df1 join df2
on df1.col1 = df2.col1 and df1.col2 = df2.col2
df = pd.merge(df1, df2, on=["col1", "col2"])
Outer Join 保留两个表单的全部内容,为无法匹配的内容填入 NaN
select * from df1 full outer join df2
on df1.col1 = df2.col1
df = pd.merge(df1, df2, on=["col1"], how="outer")
Left Join (or use right)
df = pd.merge(df1, df2, on=["col1"], how='left')
1.10 数据处理
1.10.1 Rolling
Rolling object is a kind of list contains all the windows
# roll = df.rolling(window_length)
prodroll = products.rolling(2)
products: | |Category |Price |Name |Amount| |-|———|——|——|——| |0|Drink |4 |Cola |100 | |1|Snack |10 |Nut |50 | |2|Drink |3 |Fenta |200 | |3|Drink |2 |Water |500 |
# df.rolling(window_length).col_of_interest.apply(func)
products.rolling(2).Price.apply(np.mean)
"""
0 NaN
1 7
2 6.5
3 2.5
"""
1.10.2 Statistic 统计数据
# 查看各列的统计数据(count, mean, std, percentile...)
df.describe()
df.mean() # 各列平均
df.mean(axis=1) # 各行平均
df.sum() # 各列求和。此外: std() max() min() median()
df.corr() # 各列之间的 correlation
1.10.3 Trend (Change)
数据的变化幅度(百分比)
df.pct_change()
"""
Price
0 10
1 15
2 30
3 33
>>>
Price
0 NaN
1 0.5
2 1
3 0.1
"""
1.10.4 Pivot/ Dummy Variables/ On-hot Encoding
通过 Pivot 将三种性别转化为三个 Dummy Vraibles(之后可应用于机器学习)
students: | |id |Gender| |-|—|——| |0|001|Man | |1|021|Woman | |2|241|Other |
dummies = pd.get_dummies(students["Gender"])
students_new = pd.concat([students, dummies], aixs=1)
| id | Gender | Man | Woman | Other | |
|---|---|---|---|---|---|
| 0 | 001 | Man | 1 | 0 | 0 |
| 1 | 021 | Woman | 0 | 1 | 0 |
| 2 | 241 | Other | 0 | 0 | 1 |
Dummy Varaibl Trap
观察以上 DataFrame,我们发现只需要两个 Dummy Variables 就足以区分三种性别。因此可以把第一个 Dummy 去掉
dummies = pd.get_dummies(students["Gender"], drop_first=True)
| Woman | Other | |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 0 |
| 2 | 0 | 1 |
1.11 Datetime
把 string 格式的时间转化为 Datetime 格式并添加为新的一列
df['datetime'] = pd.to_datetime(df['Date'])
2. pandas.Series
一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成
创建方式:
# 由数组创建,默认标签为数组下标
pd.Series([2, 4, 6])
# 由数组创建,并设置标签
pd.Series([2, 4, 6], index=['a', 'b' 'c'])
# 由字典创建
pd.Series({'a':2, 'b':4, 'c':6})
# 创建一个全部值为零的Series
pd.Series(0, index=['a', 'b' 'c'])
获取值数组和索引数组:
sr.index
sr.values
2.1 特性
类似array的特性(下标)
- 从ndarray创建Series
- 标量运算:
sr*2 - 两个Series运算:
sr1 + sr2sr1.add(sr2)
sr1 = pd.Series([1,2], index=['a','b'])
sr2 = pd.Series([1,2], index=['b','a'])
sr3 = pd.Series([1], index=['b'])
# 运算时会按照标签进行数据对齐
sr1 + sr2
>>>
a 3
b 3
# 缺失值相加会默认设置为NaN
sr1 + sr3
>>>
a NaN
b 3
# 但可以通过.add()设置为0
sr1.add(sr3, fill_value=0)
>>>
a 1
b 3
- 下标索引、切片:
sr.iloc[0]sr.iloc[[1, 3]]sr.iloc[0:3] - 布尔值过滤:
sr[sr>0] - 通用函数:
np.abs(sr)np.argmax(sr)...
类似字典的特性(key)
- 从字典创建Series
- 键索引:
sr.loc['a']sr.loc[['a', 'c']] - in运算查看是否包含指定key:
'a' in sr
独有特性
- 键切片(头尾均包含):
sr.loc['a':'c']
2.2 数据处理
平移 Shift
sr.shift(1) # 向右平移一个单位
缺失值 NaN
# 删除
sr = sr[sr.notnull()] # 布尔值过滤
sr = sr.dropna()
sr = sr.fillna(sr.mean()) # 替换为平均值
分组 Cut
pd.cut()
2.3 统计
sr.value_counts() # 统计每个数值出现的次数
sr.quantile(p) # 百分位:p从0至1
sr.mad() # Mean Absolute Deviation
sr.var() # 方差
sr.std() # 标准差
sr1.cov(sr2) # 协方差
sr.cumsum() # 逐个累加 [1,3,2] >>> [1,4,6]
sr.cummax() # 累计最大值 [1,3,2,4] >>> [1,3,3,4]
sr.cumprod() # 累乘(累积)
2.4 Plot
# Line Chart(横坐标为 Index)
sr.plot()
# Bar Chart: 显示每个元素出现的次数
sr.value_counts().plot(kind='bar')
2.5 分组
# pd.cut(numerical_series, edge_numbers_to_split_by, labels_for_groups)
pd.cut(sr, [-1, 50, 100], [1,2]) # 分成两组 1:[-1,50) 2:[50,100)
3. Time Series
3.1 创建 datetime 对象
# 将数据表的一列字符串格式的时间转换为 datetime
df['date'] = pd.to_datetime(df['date'])
# 将字符串格式的时间批量转换为 datetime
pd.to_datetime(['2011-01-11', '2021/FEB/22'])
创建一段时间range
# 生成一个包含了,从1月11到1月22之间,共12天日期的数组
pd.date_range('2011-01-11', '2011-01-22')
# 从1月11开始往后,共20天的日期
pd.date_range('2011-01-11', peirods=20)
更改频率 freq=
'D'day, default'H'hour'W'week,'W-MON'表示每个周一'M'mounth'B'work day'A'year- 其它一些自定义,例如
'1h20min'表示间隔1时20分钟
# 从1月11日0点开始往后,共20小时的时间
pd.date_range('2011-01-11', periods=20, freq='H')
# 从1月11往后的第一个周二开始,共20个周二的日期
pd.date_range('2011-01-11', periods=20, freq='W-TUE')
3.2 时间序列
以 datetime 对象为索引的 Series 或 DataFrame,例如
sr = pd.Series(np.arange(11), pd.date_range('2011-01-22', period=11))
时间序列的便利性
# 切片
sr['2011-01'] # 切片,包含所有索引为2011年1月的数据
sr['2011'] # ...索引为2011年...
sr['2011-01-11':'2012-02']
# 统计
sr.resample('W').sum() # 将每周的数据求和
sr.resample('M').mean() # 求每月数据的均值
sr.resample('M').first()# 第一条记录
sr.resample('M').last() # 最后一条
Document Information
- Author: Zeka Lee
- Link: https://zhekaili.github.io/wiki/python-libs/python-lib-pandas/
- Copyright: 自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)