http协议 常用请求头信息
- User-Agent: 请求载体的身份表示(例如:谷歌游览器)
- Connection: 请求完毕之后,是断开还是爆出链接
常用响应头信息
- Content-Type: 服务器响应客户端的数据类型
https协议 安全的超文本传输协议
1. requests 模块
主要网络请求模块:urllib & requests (better)
作用: 模拟游览器发送请求
编码流程:
- 指定 url
- 发起请求
- 获取响应数据
- 持久化存储
import requests
# 指定 url
url = 'https://www.sogou.com'
# 发起请求
response = requests.get(url=url)
# 获取响应数据
page_text = response.text
print(page_text)
# 持久化存储
with open('./sogou.html', 'w', encoding='utf-8') as f:
f.write(page_text)
1.1 案例一:使用搜狗搜索
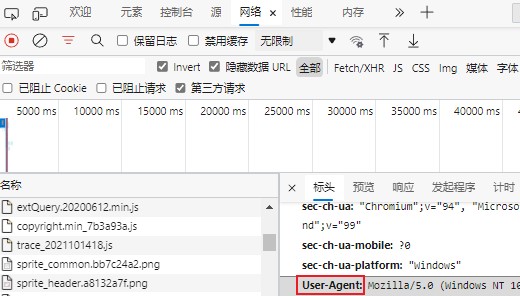
UA伪装: 通过更改请求头的方式将爬虫访问伪装为正常的游览器访问(可在下图位置查看)
# 指定 url
url = 'https://www.sogou.com/web'
# 发起请求
params = {
'query': 'python'
}
## UA伪装(伪装成游览器)
headers = {
'User-Agent': '...'
}
response = requests.get(url=url, params=params, headers=headers)
# 获取响应数据
page_text = response.text
print(page_text)
# 持久化存储
with open('./sogou.html', 'w', encoding='utf-8') as f:
f.write(page_text)
1.2 案例二:使用百度翻译
本案例的核心不是代码,而是如何分析抓包结果
Step-1: 分析刷新形式
在文字栏中输入 ‘dog’, 发现整个网页并没有刷新,而是在原网页的基础上添加了一块有关翻译内容的界面,因此断定其使用的是 Ajex 请求,这提示我们可以查看 Fetch/XHR 栏的抓包情况。
输入栏为空白:
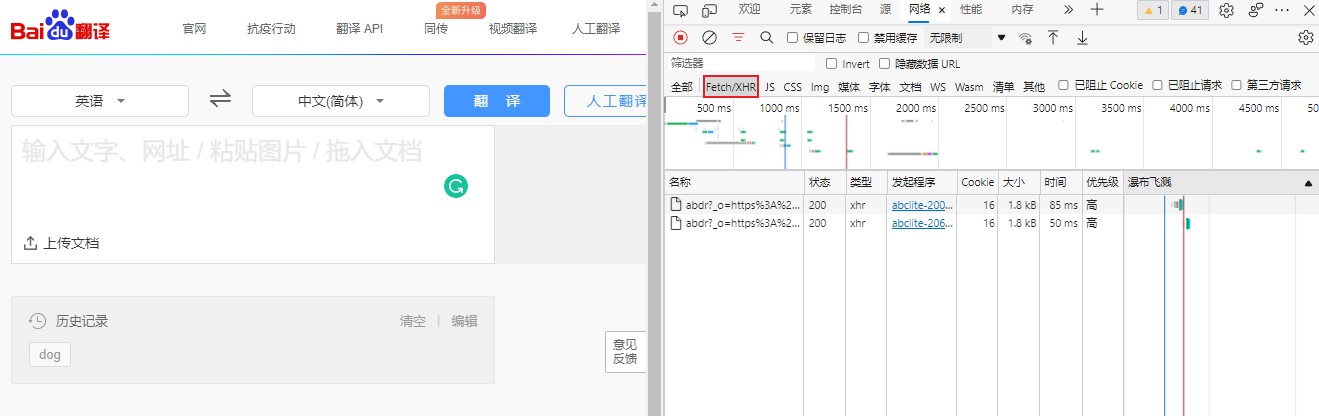
Step-2: 分析包
输入 ‘dog’ 之后,我们发现增加了好多包,对此我们需要进行逐一分析:
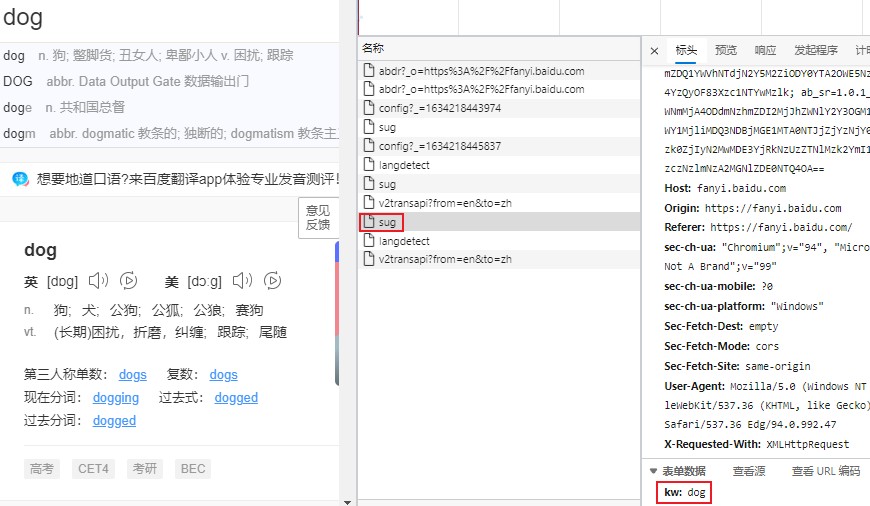
- 初步查看
标头信息后发现第三个名为 ‘sug’ 的包很可疑,因为其表单数据里的内容很符合我们的预期 - 进一步查看该包的
响应/Response栏,发现里边包含了 ‘dog’, ‘n.’ 和一些编码信息,从而基本确定这个包就是我们想要的
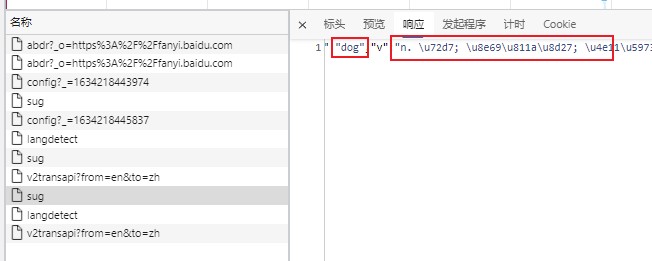
Step-3: 提取必要信息
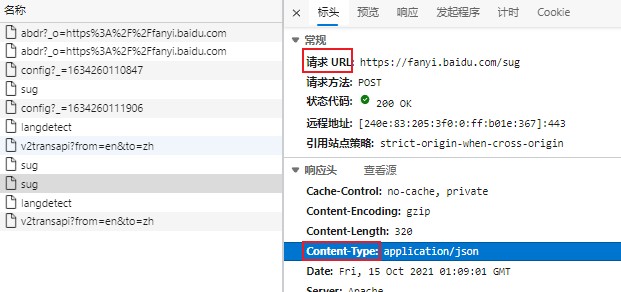
在这个案例中,我们主要需要提取两个信息: 请求 URL 与 响应头 - Content-Type
请求 URL提供了requests.post()的对象信息响应头 - Content-Type说明了响应数据的数据类型
如下图,可得响应信息的格式为 json
代码:
import json
# 指定 url
url = 'https://fanyi.baidu.com/sug'
# 发起请求
params = {
'kw': 'dog'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.47'
}
response = requests.post(url=url, params=params, headers=headers)
# 获取响应数据
dic_obj = response.json()
print(dic_obj)
# 持久化存储
with open('./dog.json', 'w', encoding='utf-8') as f:
json.dump(dic_obj, fp=f, ensure_ascii=False)
1.3 案例三:获取豆瓣电影信息
Step-1: 分析刷新形式
以喜剧电影榜单为例,下滑页面时发现会存在实时刷新的现象(刷新出更多的电影信息),因此我们可以检查一下 Fetch/XHR 栏的抓包情况。
Step-2: 分析包 + 提取必要信息
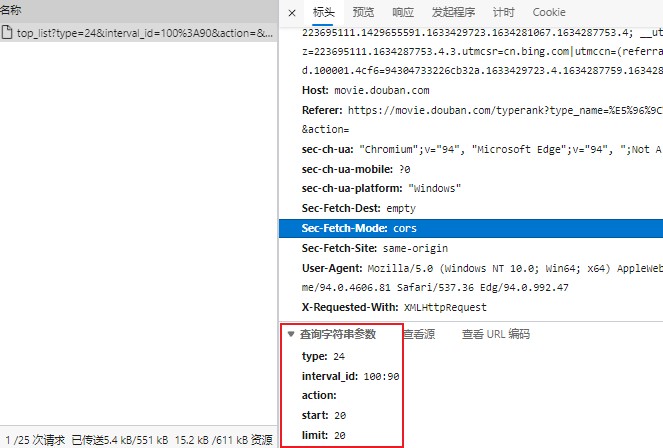
果然出现了一个包,查看其 响应/Response 栏内容,确实为电影信息。进一步提取必要信息如下:
请求 URL: https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=20&limit=20响应头 - Content-Typejson 文件
在 请求 URL 中的问号之后的信息,可以在 查询字符串参数 中找到,从而在具体代码中可将其设置 .get() 或 .post() 的 params 参数:
代码:
# 指定 url
url = 'https://movie.douban.com/j/chart/top_list'
# 发起请求
params = {
'type_name': '喜剧',
'type': '24',
'interval_id': '100:90',
'action': '',
'start': '0', # 从库中的第几个电影开始取
'limit': '20' # 一次取的个数
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.47'
}
response = requests.get(url=url, params=params, headers=headers)
# 获取响应数据
list_data = response.json()
# 持久化存储
with open('./douban.json', 'w', encoding='utf-8') as f:
json.dump(list_data, fp=f, ensure_ascii=False)
Document Information
- Author: Zeka Lee
- Link: https://zhekaili.github.io/wiki/python/python-crawler/
- Copyright: 自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)